Full repo here.
Classification is one of the core problems of machine learning. Just a few years back, we would bestow those who won a classification competition on Kaggle with the title of Grandmaster. It was a time of extensive manual coding and hyper-parameter optimization to achieve effective results.
For companies looking to integrate this technology into their business, the process was time-consuming, often spanning the entire machine learning operations lifecycle from data preparation to model deployment.
Today's landscape is a bit different now that LLMs are here. These models can perform classification tasks directly from a prompt, delivering state-of-the-art performance with significantly reduced complexity and time investment.
Classification Using GPT-3.5 & GPT-4
We'll start with using GPT-3.5 and GPT-4 to show how classification can be done with natural language queries. We'll be using the financial_phrasebank dataset from HuggingFace, which is a sentiment dataset of sentences from financial news. Each entry in the dataset consists of a sentence related to finance, and a label of either Neutral, Positive, or Negative.
Here's an example:
Sentence: In Q2 of 2009, profit before taxes amounted to EUR 13.6 mn, down from EUR 26.8 mn in Q2 of 2008.
Label
The model has to understand the because the profit went down, then the sentiment is negative. Let's see how the models perform at this, using the OpenAI playground.
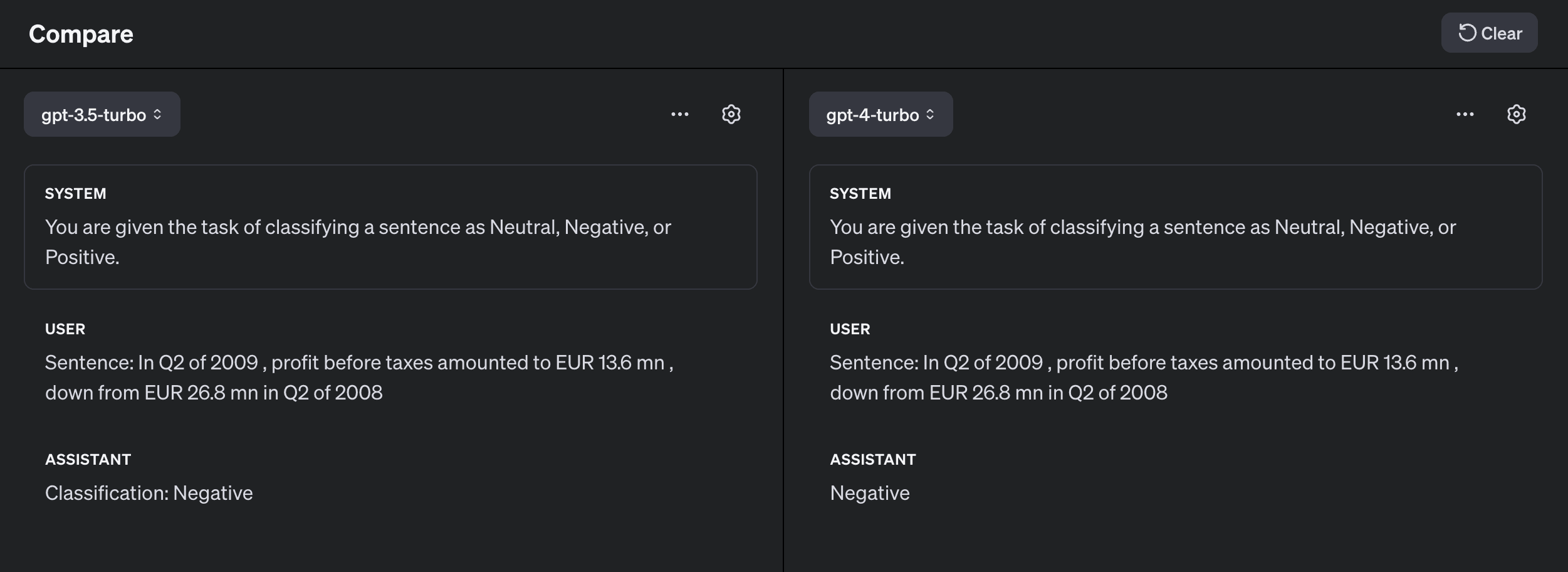
Great! Both models were able to properly classify this sentence as negative.
This is important for so many reasons.
You can now deploy classification models at scale in minutes. What used to be a job for a small team of ML engineers, has now become doable for non-technical people.
You can iterate over your prompts much faster than you can iterate over an SVM or a random forest model. This allows companies to ship more classifiers, which directly increases the efficiency of the business.
With less focus on how to get these classifiers to work, you can now focus on what actually matters: analyzing the results.
Problems with Classification Using GPT-3.5 & GPT-4
We only saw one example where the models correctly labeled the sentence. Let's try another:
Sentence: Compared with the FTSE 100 index, which rose 36.7 points (or 0.6%) on the day, this was a relative price change of -0.2%.
Label
Trying this out in the playground:
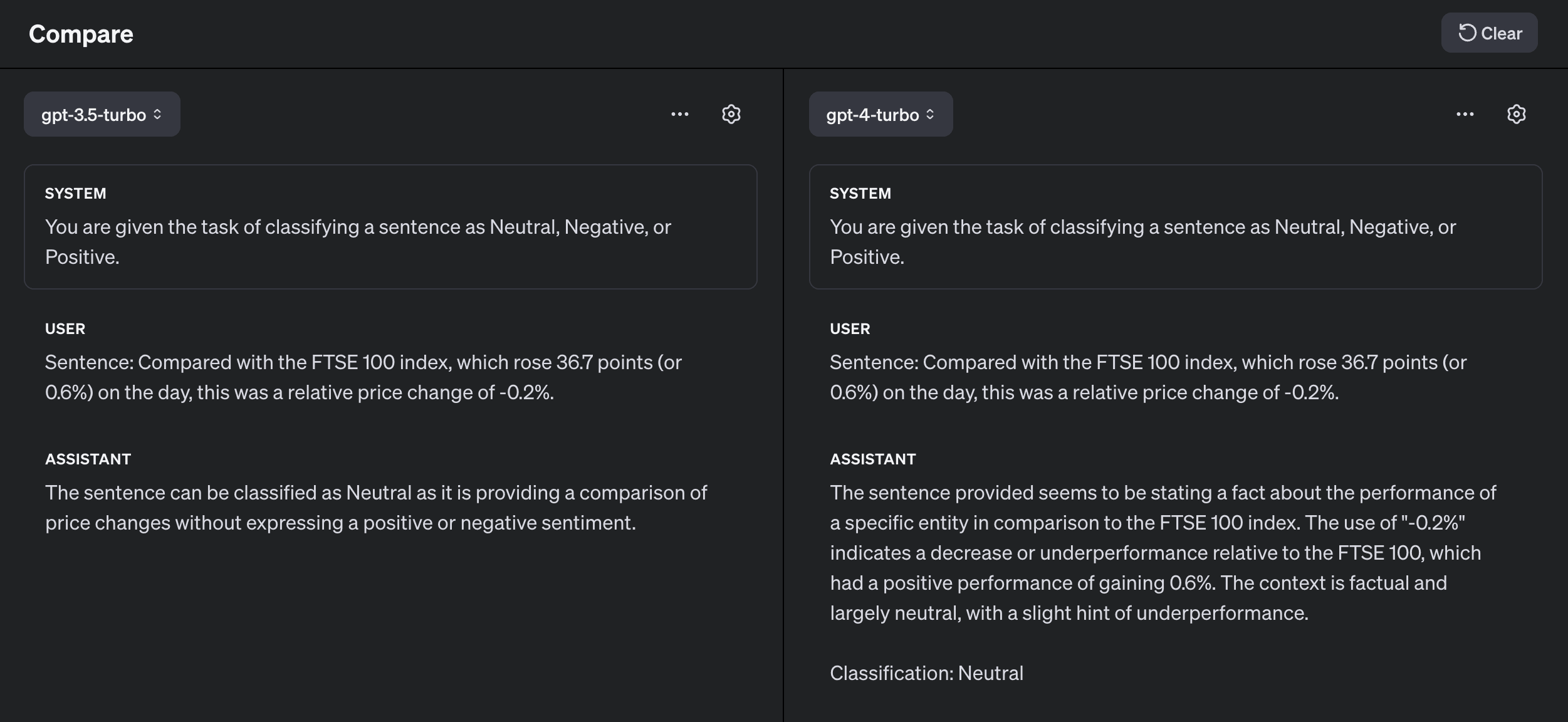
Both GPT-3.5 and GPT-4 got it wrong! The good news is we can use some advanced prompting techniques, like Chain of Thought, to get it to work.
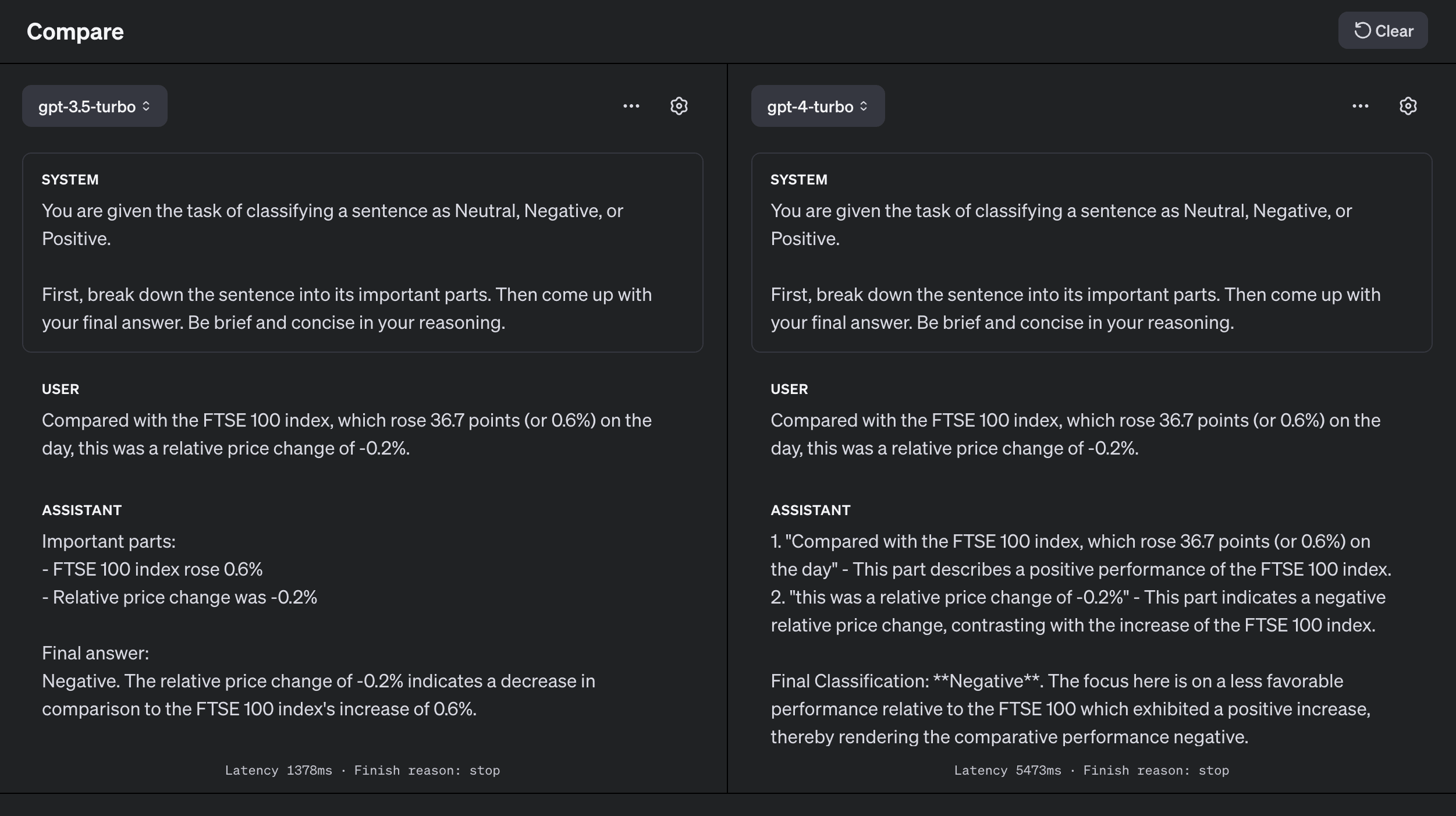
That worked!
Productionizing Classification
Now that we have a prompt that seems to work, let's test it out on the whole dataset. We're going to use the sentences_allagree subset, which has 100% annotator agreement among 2,264 samples.
Let's setup the project. Ensure you have git-lfs installed to load the HuggingFace dataset. The rest of this tutorial will be assuming you're on Mac.
Then clone the repo and unzip the dataset
git clone https://huggingface.co/datasets/financial_phrasebank
cd
You'll find a FinancialPhraseBank-v1.0/Sentences_AllAgree.txt file. This is the dataset we'll be using. It should look like:
According to Gran, the company has no plans to move all production to Russia, although that is where the company is growing.@neutral
...
Let's setup a simple Node.js environment to run our scripts.
npm init
tsc --init
npm i montelo openai dotenv
npm i @types/node --save-dev
Head over to your Montelo project and get the API key for your environment. Also have your OpenAI key on hand.
OPENAI_API_KEY=sk-XXX
MONTELO_API_KEY
Setup the Montelo client to be used across our scripts.
import { Montelo } from "montelo";
export const montelo = new Montelo();
Now let's upload the dataset to Montelo. First we'll define the types for our project.
export type Sentiment = "neutral" | "positive" | "negative";
export type HuggingFaceDatapoint = {
sentence: string;
sentiment: Sentiment;
};
export type DInput = {
sentence: string;
};
export type DOutput = {
sentiment: Sentiment;
};
export type DEvaluation = {
isCorrect: boolean;
};
export type FineTuneDInput = {
messages: Array<{
role: "system" | "user" | "assistant";
content: string;
}>;
};
export type FineTuneDOutput = {
messages: Array<{
role: "system" | "user" | "assistant";
content: string;
}>;
};
And we'll write a quick utility function to read the dataset:
import fs from "fs";
import { HuggingFaceDatapoint, Sentiment } from "./types";
export const readHuggingFaceDataset = (): HuggingFaceDatapoint[] => {
const filePath = "./FinancialPhraseBank-v1.0/Sentences_AllAgree.txt";
const fileContent = fs.readFileSync(filePath, 'utf8');
const allLines = fileContent.split('\n');
return shuffle(allLines).slice(0, 200).reduce((accum, line) => {
const trimmed = line.trim();
const parts = trimmed.split('@');
if (parts.length !== 2) {
return accum;
}
const sentence = parts[0].trim();
const sentiment = parts[1].trim() as Sentiment;
return [...accum, {
sentence,
sentiment,
}];
}, [] as HuggingFaceDatapoint[]);
};
export const chunk = <T>(arr: T[], size: number): Array<T[]> =>
Array.from({ length: Math.ceil(arr.length / size) }, (_: any, i: number) =>
arr.slice(i * size, i * size + size)
);
export const shuffle = <T>(array: T[]): T[] => {
let currentIndex = array.length, randomIndex;
while (currentIndex != 0) {
randomIndex = Math.floor(Math.random() * currentIndex)
Now let's upload the dataset to Montelo.
import "dotenv/config";
import { readHuggingFaceDataset } from "./utils";
import { montelo } from "./montelo";
import { DInput, DOutput } from "./types";
const upload = async () => {
const dataset = await montelo.datasets.create({
name: "Financial Phrase Bank",
description: "This is only the subset for all agree.",
inputSchema: { sentence: "string" },
outputSchema: { sentiment: "string" },
});
const datapoints = readHuggingFaceDataset();
const formattedDatapoints = datapoints.map((datapoint) => ({
input: { sentence: datapoint.sentence },
expectedOutput: { sentiment: datapoint.sentiment },
split: Math.random() < 0.7 ? "TRAIN" as const : "TEST" as const,
}));
await montelo.datapoints.createMany<DInput, DOutput>({
dataset: dataset.slug,
datapoints: formattedDatapoints,
});
};
void upload();
Once you have that setup, just run tsx upload.ts, and wait for the upload to finish (it should take ~2 seconds).
Let's make sure everything looks good on the UI.
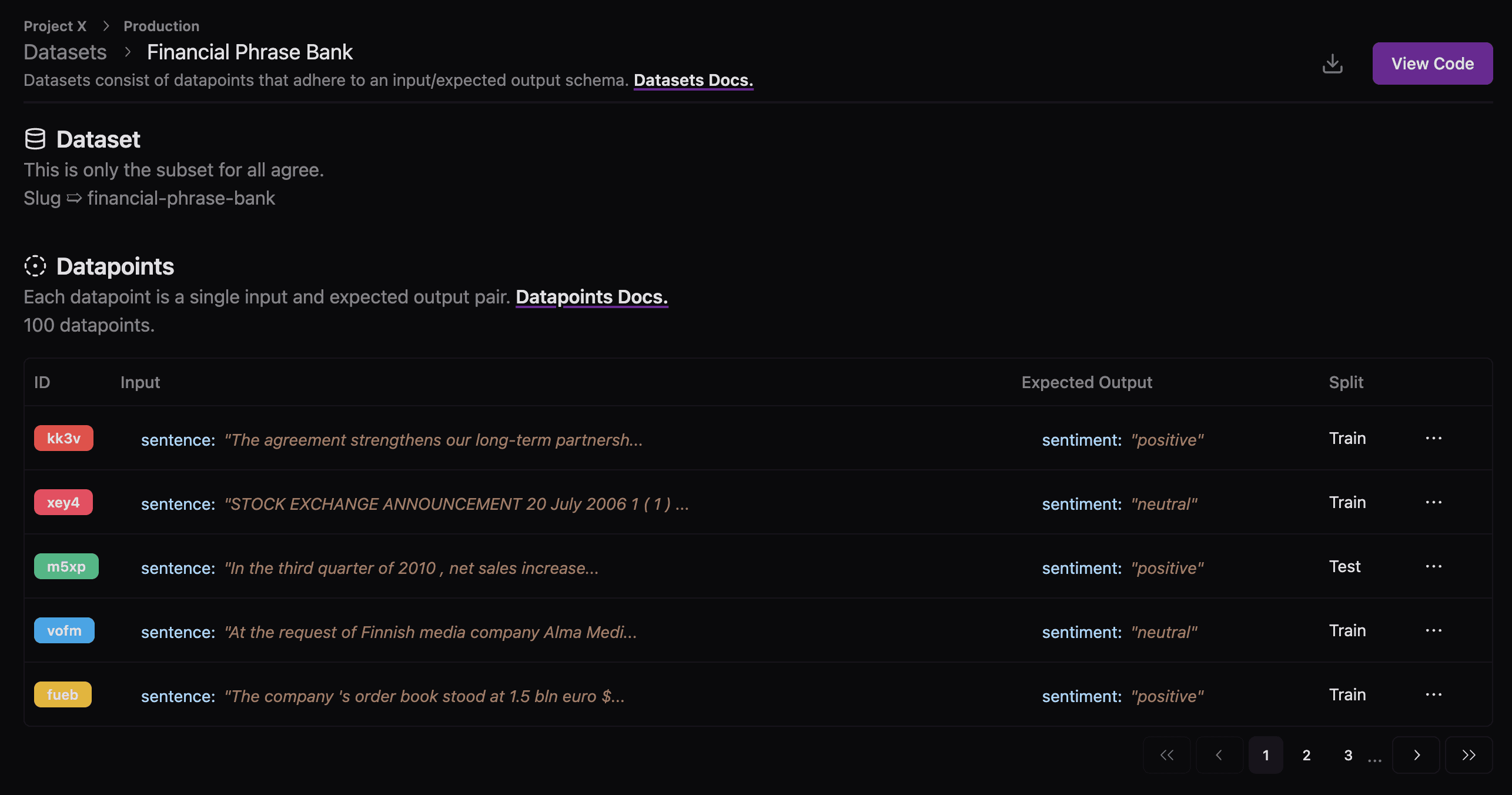
Great!🎉 Now let's run a couple experiments on this dataset. The first experiment will test GPT-4 and the second will test GPT-3.5. Let's set this up.
import "dotenv/config";
import { DEvaluation, DInput, DOutput, Sentiment } from "./types";
import { CLASSIFICATION_SYSTEM_PROMPT } from "./prompts";
import { montelo } from "./montelo";
const llmRequest = async (sentence: string, model: "gpt-4-turbo" | "gpt-3.5-turbo"): Promise<Sentiment> => {
const completion = await montelo.openai.chat.completions.create({
model,
messages: [
{
role: "system",
content: CLASSIFICATION_SYSTEM_PROMPT
},
{
role: "user",
content: `Sentence: ${sentence}`
}
],
response_format: {
type: "json_object",
}
});
const message = completion.choices[0].message.content;
if (!message) {
throw new Error("Model returned null message");
}
const parsed = JSON.parse(message) as { reasoning: string; label: string };
return parsed.label.toLowerCase() as Sentiment;
};
const evaluator = async (expectedSentiment: string, actualSentiment: string): Promise<DEvaluation> => {
return {
isCorrect: expectedSentiment === actualSentiment,
}
};
const experiment = async () => {
const dataset = "financial-phrase-bank";
await montelo.experiments.createAndRun<DInput, DOutput, DEvaluation>({
name: "Run 1: GPT-4 Turbo",
description: "Running GPT-4 Turbo",
dataset,
runner: async (input) => {
const gpt4 = await llmRequest(input.sentence, "gpt-4-turbo");
return { sentiment: gpt4 }
},
evaluator: async ({ expectedOutput, actualOutput }) => {
return evaluator(expectedOutput.sentiment, actualOutput.sentiment);
},
options: { parallelism: 10 }
});
await montelo.experiments.createAndRun<DInput, DOutput, DEvaluation>({
name: "Run 2: GPT-3.5 Turbo",
description: "Running GPT-3.5 Turbo",
dataset,
runner: async (input) => {
const gpt3 = await llmRequest(input.sentence, "gpt-3.5-turbo");
return { sentiment: gpt3 }
},
evaluator: async ({ expectedOutput, actualOutput }) => {
return evaluator(expectedOutput.sentiment, actualOutput.sentiment);
},
options: { parallelism: 10 }
});
};
void experiment();
Once that's done, we can take a look at the results side-by-side on the dashboard.
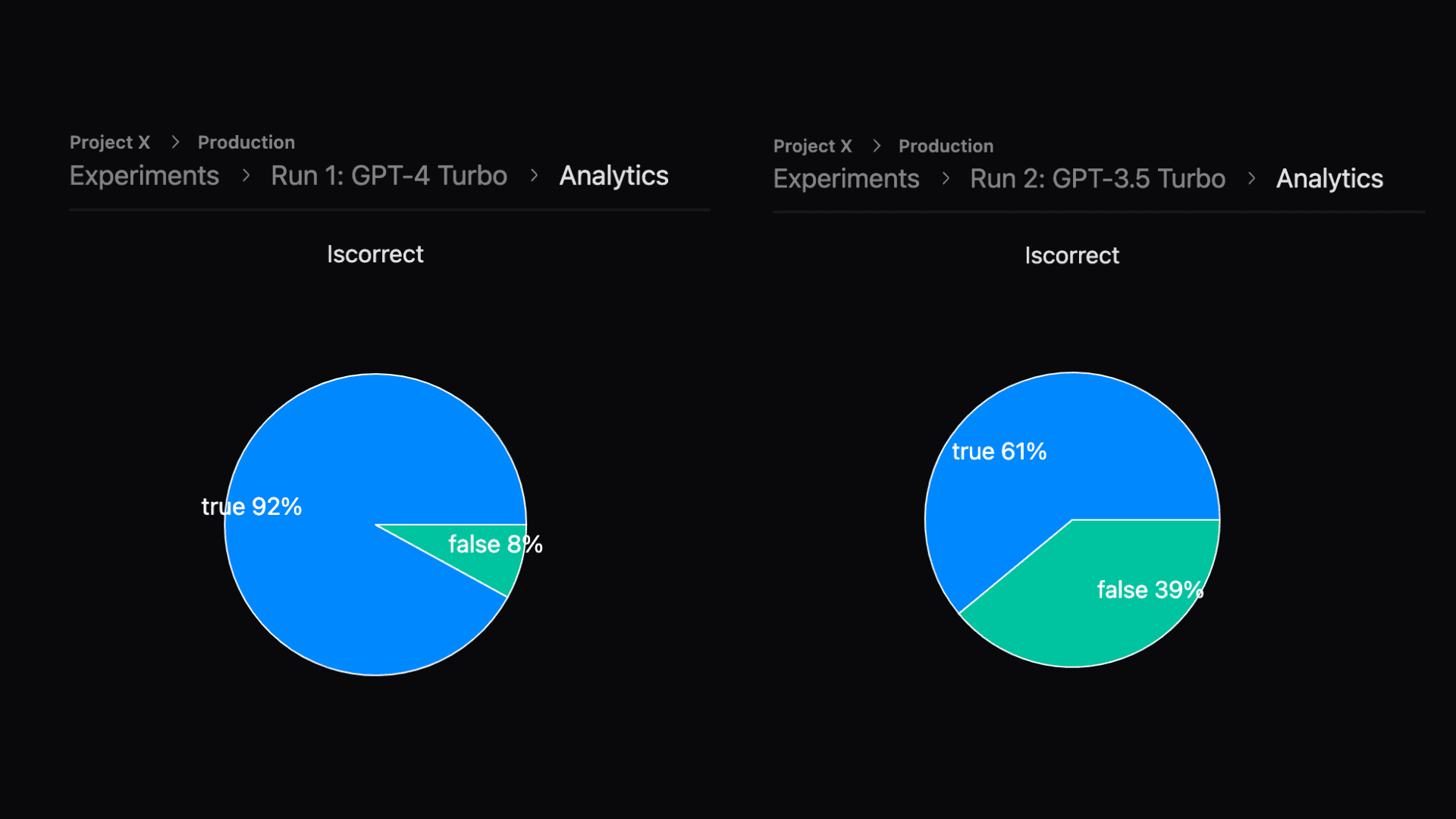
We can see that GPT-4 does really well at 92% accuracy, but GPT-3.5 struggles a lot, at 61% accuracy. Both are actually unusable in a production environment, because GPT-4 costs a lot and is really slow, and GPT-3.5 just isn't reliable enough.
The Solution: Fine-Tune GPT-3.5
We can have GPT-3.5 achieve GPT-4 level quality by fine-tuning it on the specific task. Let's see exactly what this means.
First we have to prepare the dataset. Fine-tuning GPT-3.5 requires a dataset in the chat format. Here's an example datapoint for fine-tuning:
{
"messages": [
{
"role": "system",
"content": "Marv is a factual chatbot that is also sarcastic."
},
{
"role": "user",
"content": "What's the capital of France?"
},
{
"role": "assistant",
"content": "Paris, as if everyone doesn't know that already."
}
]
}
In our case, we need to convert our dataset from HuggingFace to the above format, so it would look like this:
{
"messages": [
{
"role": "system",
"content": "You are given the task of classifying a sentence as neutral, negative, or positive. First, try to reason over the problem, then come up with the answer. Return your answer in JSON format as type { reasoning: string, label: string }. Be brief and concise in your reasoning."
},
{
"role": "user",
"content": "Sentence: At 1411 CET, ArcelorMittal had lost 7.26 % to EUR 17.38 on Euronext Paris, coming at the lead of the blue-chip fallers."
},
{
"role": "assistant",
"content": "{\n \"reasoning\": \"The sentence states that ArcelorMittal's stock price decreased by 7.26%, indicating a significant drop in value, which is typically viewed negatively in financial contexts.\",\n \"label\": \"negative\"\n}"
}
]
}
To do this, we could either go over each datapoint and manually write the final assistants output, or we could use GPT-4! GPT-4 is great at creating synthetic data.
Here's all you need to do to get GPT-4 to generate synthetic data for us.
import "dotenv/config";
import { FineTuneDInput, FineTuneDOutput, HuggingFaceDatapoint } from "./types";
import { CLASSIFICATION_SYSTEM_PROMPT, SYNTHETIC_DATA_SYSTEM_PROMPT } from "./prompts";
import { montelo } from "./montelo";
import { chunk, readHuggingFaceDataset } from "./utils";
import { Datapoint } from "@montelo/core/dist/bundle-node/core/MonteloDatapoints.types";
const getSyntheticData = async (datapoint: HuggingFaceDatapoint): Promise<string> => {
const completion = await montelo.openai.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [
{
role: "system",
content: SYNTHETIC_DATA_SYSTEM_PROMPT,
},
{
role: "user",
content: `Sentence: ${datapoint.sentence}\n\nLabel: ${datapoint.sentiment}`,
}
],
response_format: { type: "json_object" },
});
return completion.choices[0].message.content!;
}
const upload = async () => {
const dataset = await montelo.datasets.createFineTune({
name: "Full Financial Dataset",
description: "For Fine-Tuning. This is only the subset for all agree.",
});
const datapoints = readHuggingFaceDataset();
const chunks = chunk(datapoints, 10);
let idx = 0;
for await (const chunk of chunks) {
console.log(`Processing chunk ${idx++}/${chunks.length}`);
const syntheticData = await Promise.all(chunk.map(getSyntheticData));
const datapoints: Array<Datapoint<FineTuneDInput, FineTuneDOutput>> = chunk.map((datapoint, index) => {
return {
input: {
messages: [
{
role: "system" as const,
content: CLASSIFICATION_SYSTEM_PROMPT
},
{
role: "user" as const,
content: `Sentence: ${datapoint.sentence}`
}
],
},
expectedOutput: {
messages: [
{
role: "assistant" as const,
content: syntheticData[index],
}
],
},
split: Math.random() < 0.7 ? "TRAIN" as const : "TEST" as const,
metadata: {
sentence: datapoint.sentence,
sentiment: datapoint.sentiment,
}
}
});
await montelo.datapoints.createMany<FineTuneDInput, FineTuneDOutput>({
dataset: dataset.slug,
datapoints,
});
}
};
void upload();
And that's it! Here's what the new dataset should look like:
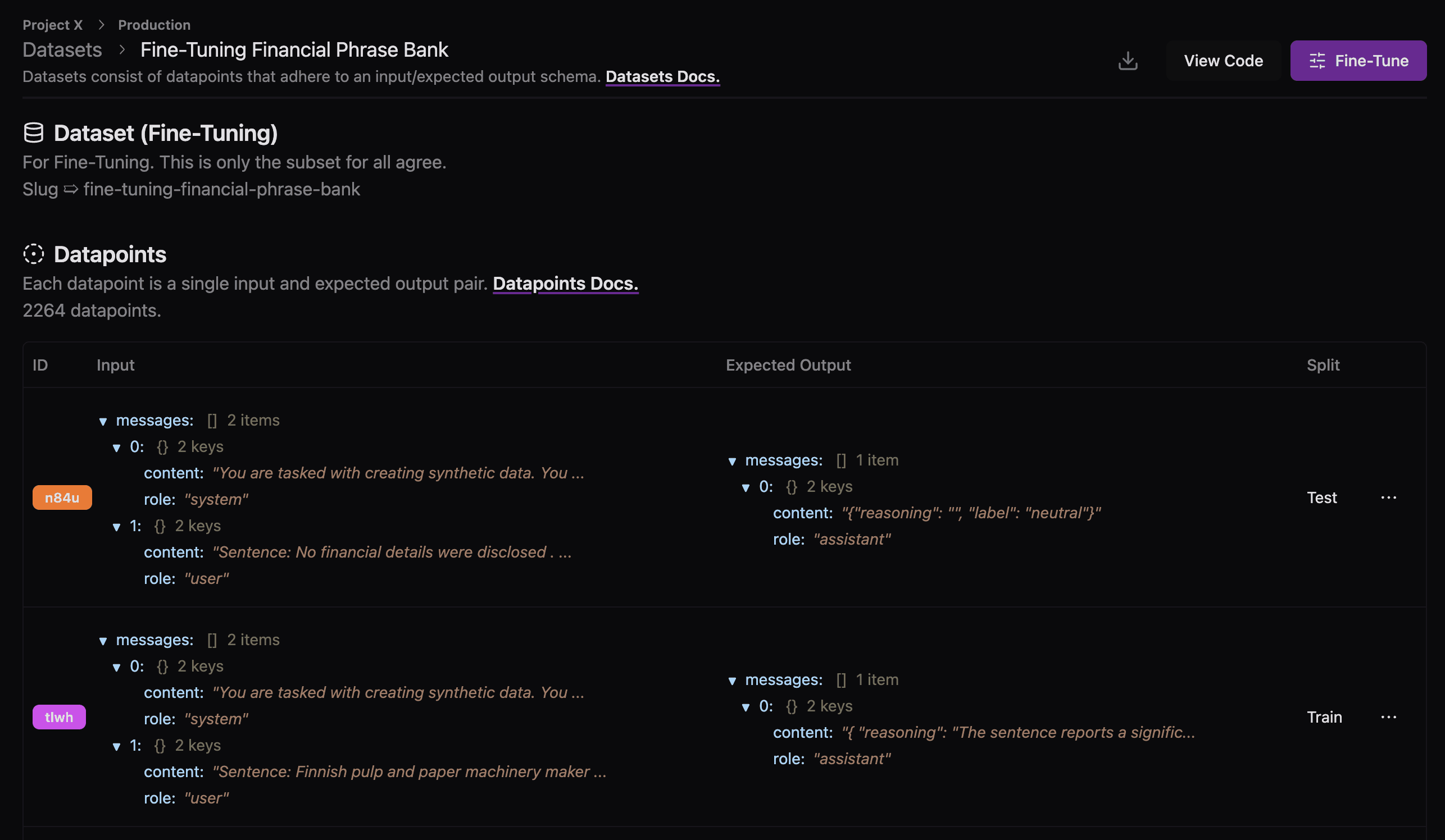
Let's go ahead and fine-tune this dataset from the UI. We're going to fine-tune a gpt-3.5-turbo-0125 model.
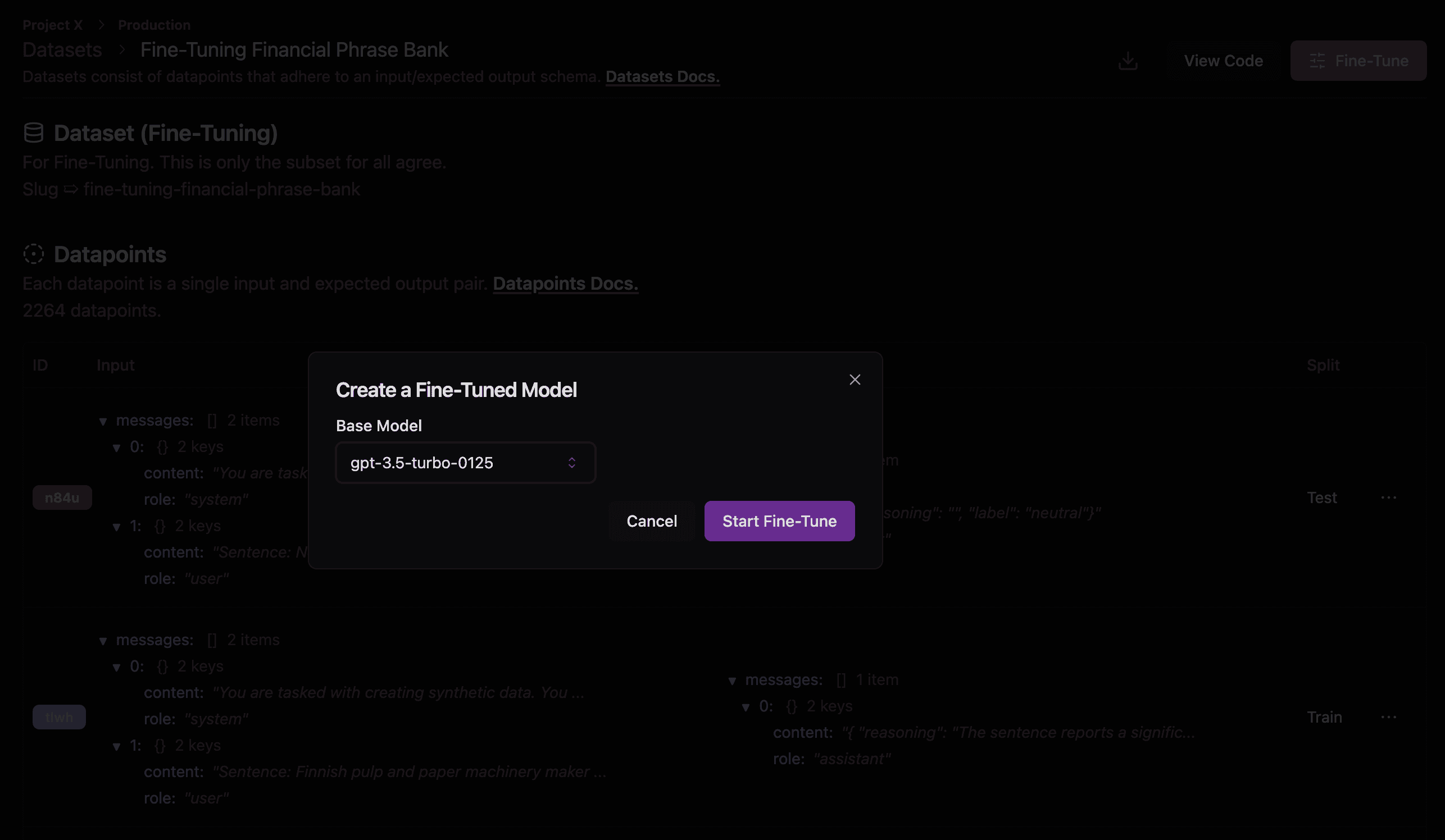
Click Start Fine-Tune to get it going! You can track its progress on the Fine-Tuning page

Once that's finished, we can run an experiment to check how well its performing.
import "dotenv/config";
import { DEvaluation, FineTuneDInput, FineTuneDOutput } from "./types";
import { CLASSIFICATION_SYSTEM_PROMPT } from "./prompts";
import { montelo } from "./montelo";
const llmRequest = async (inp: FineTuneDInput): Promise<FineTuneDOutput> => {
const completion = await montelo.openai.chat.completions.create({
model: "ft:gpt-3.5-turbo-0125:personal::9GfNUV3x",
messages: [
{
role: "system",
content: CLASSIFICATION_SYSTEM_PROMPT,
},
{
role: inp.messages[1].role,
content: inp.messages[1].content.replace("\n", "").replace(/Label: \S+/g, ""),
}
],
response_format: {
type: "json_object",
},
});
const message = completion.choices[0].message;
if (!message) {
throw new Error("Model returned null message");
}
return { messages: [message as any] };
};
const experiment = async () => {
await montelo.experiments.createAndRun<FineTuneDInput, FineTuneDOutput, DEvaluation>({
name: "Run 3: Fine-tuned GPT-3.5 ",
description: "Running a fine-tune of GPT-3.5",
dataset: "fine-tuning-financial-phrase-bank",
runner: llmRequest,
evaluator: async ({ expectedOutput, actualOutput }) => {
const expectedLabel = JSON.parse(expectedOutput.messages[0].content).label as string;
const actualLabel = JSON.parse(actualOutput.messages[0].content).label as string;
return {
isCorrect: expectedLabel.toLowerCase() === actualLabel.toLowerCase(),
}
},
options: {
parallelism: 10,
onlyTestSplit: true,
}
});
};
void experiment();
And here are the results across all three experiments:
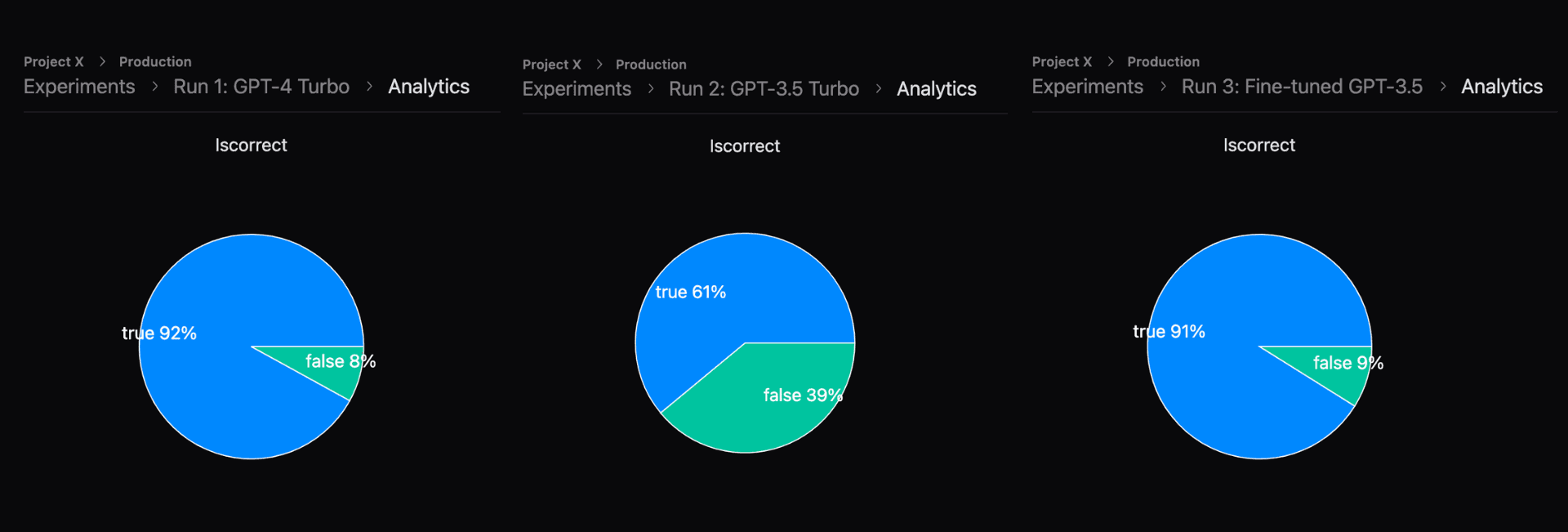
There you have it! GPT-3.5 is now as good as GPT-4, with a fraction of the latency.
Full repo here.

